BibTeX
If you find this project helpful, please cite the following papers:
@inproceedings{li2025mminference,
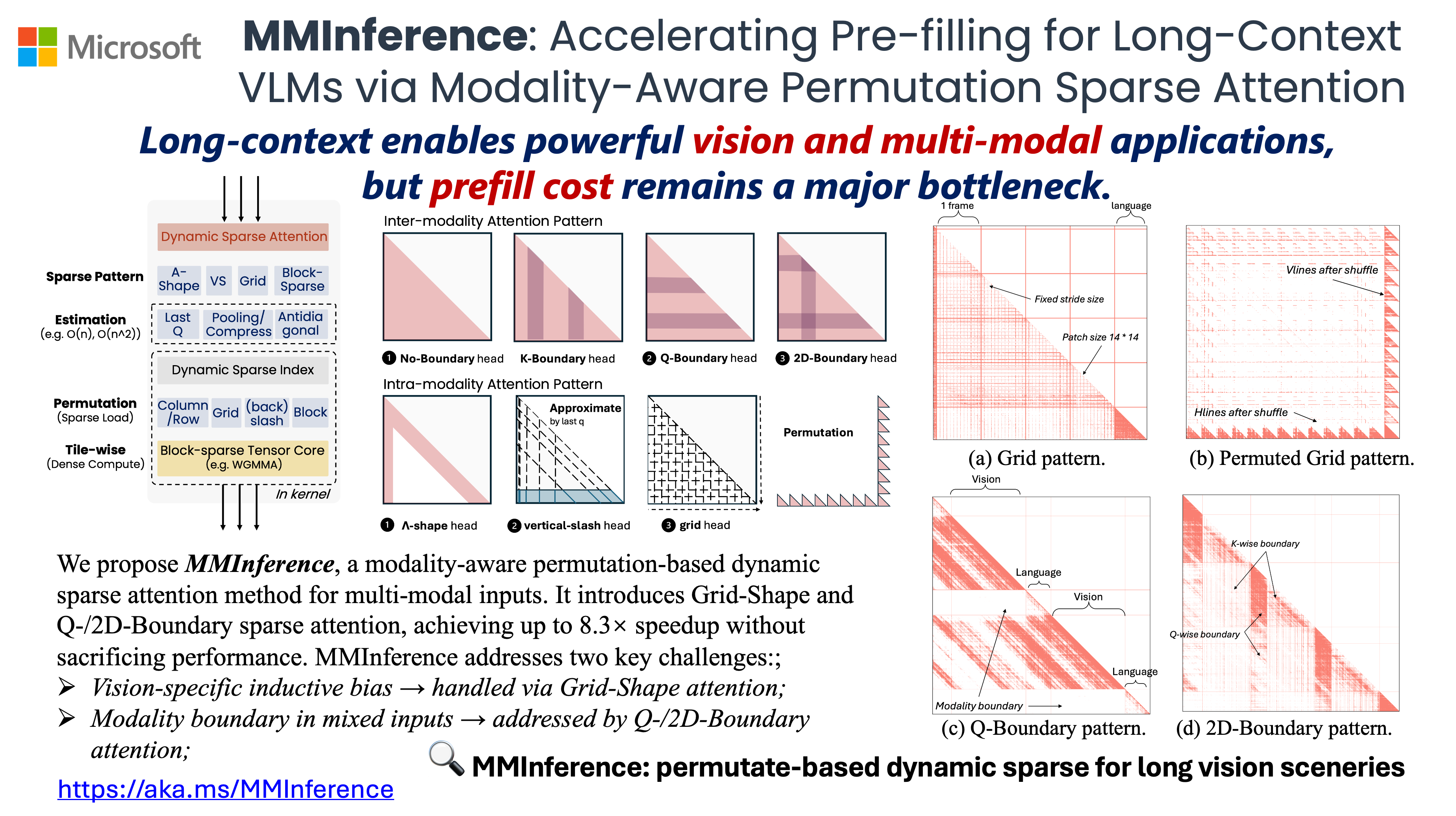
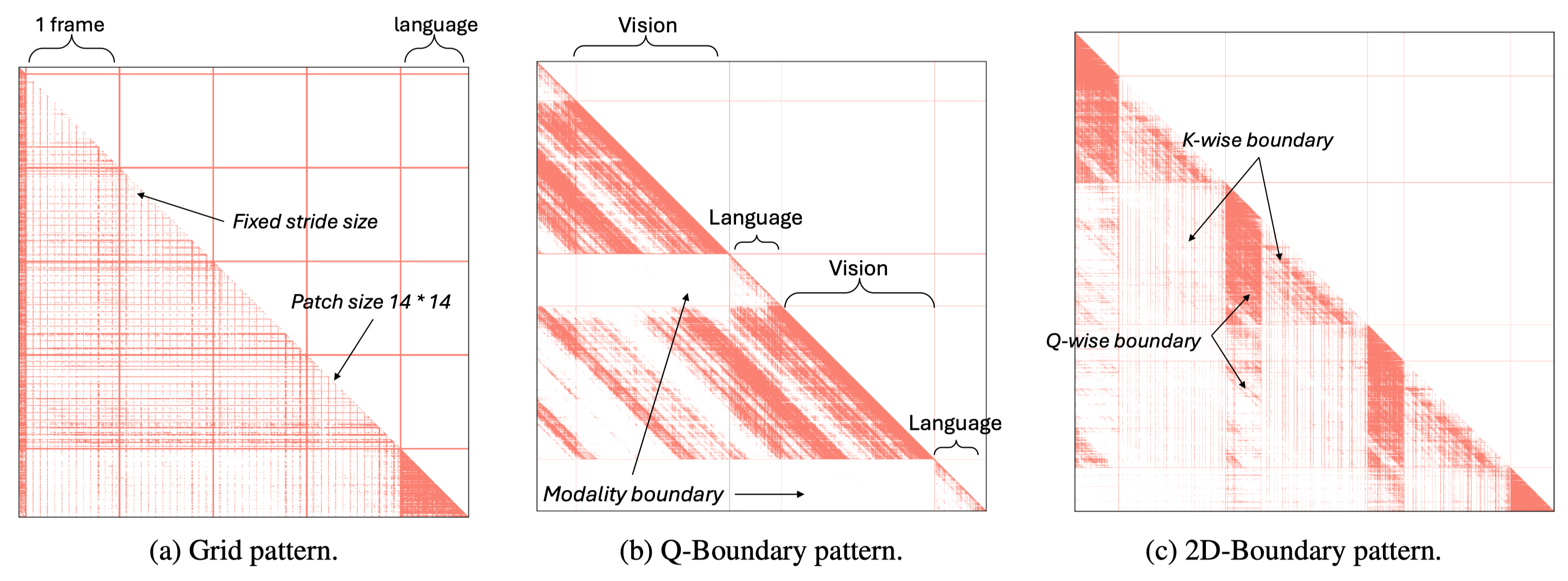
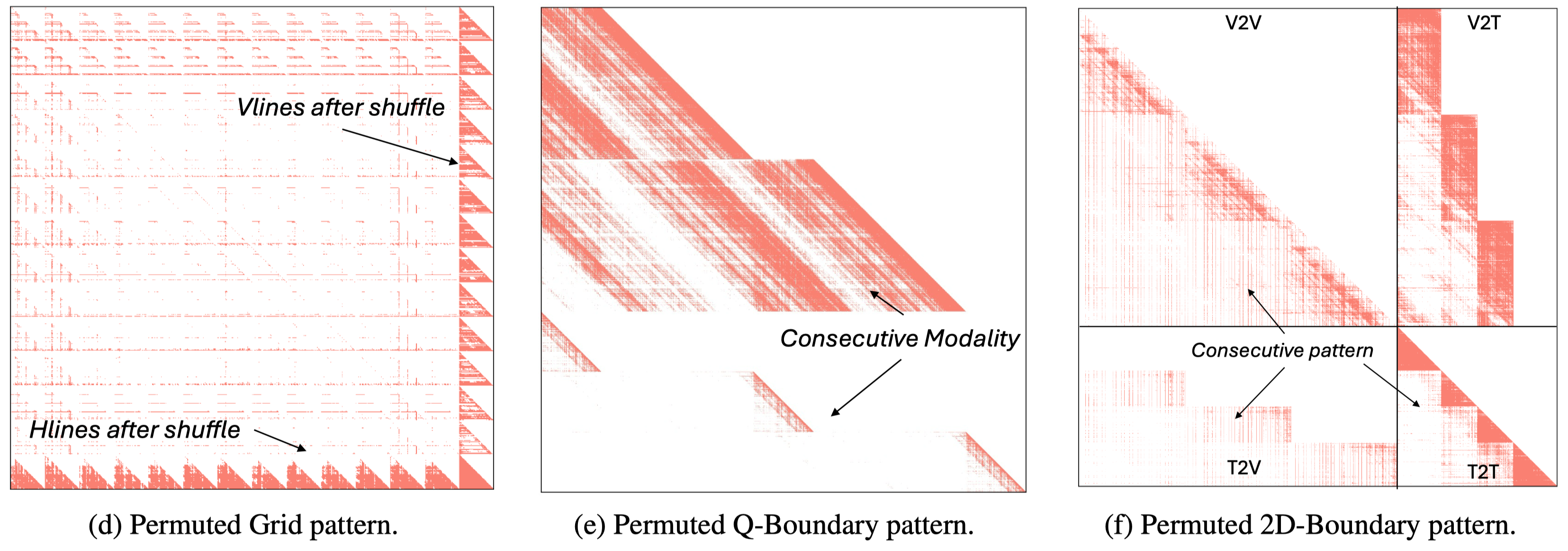
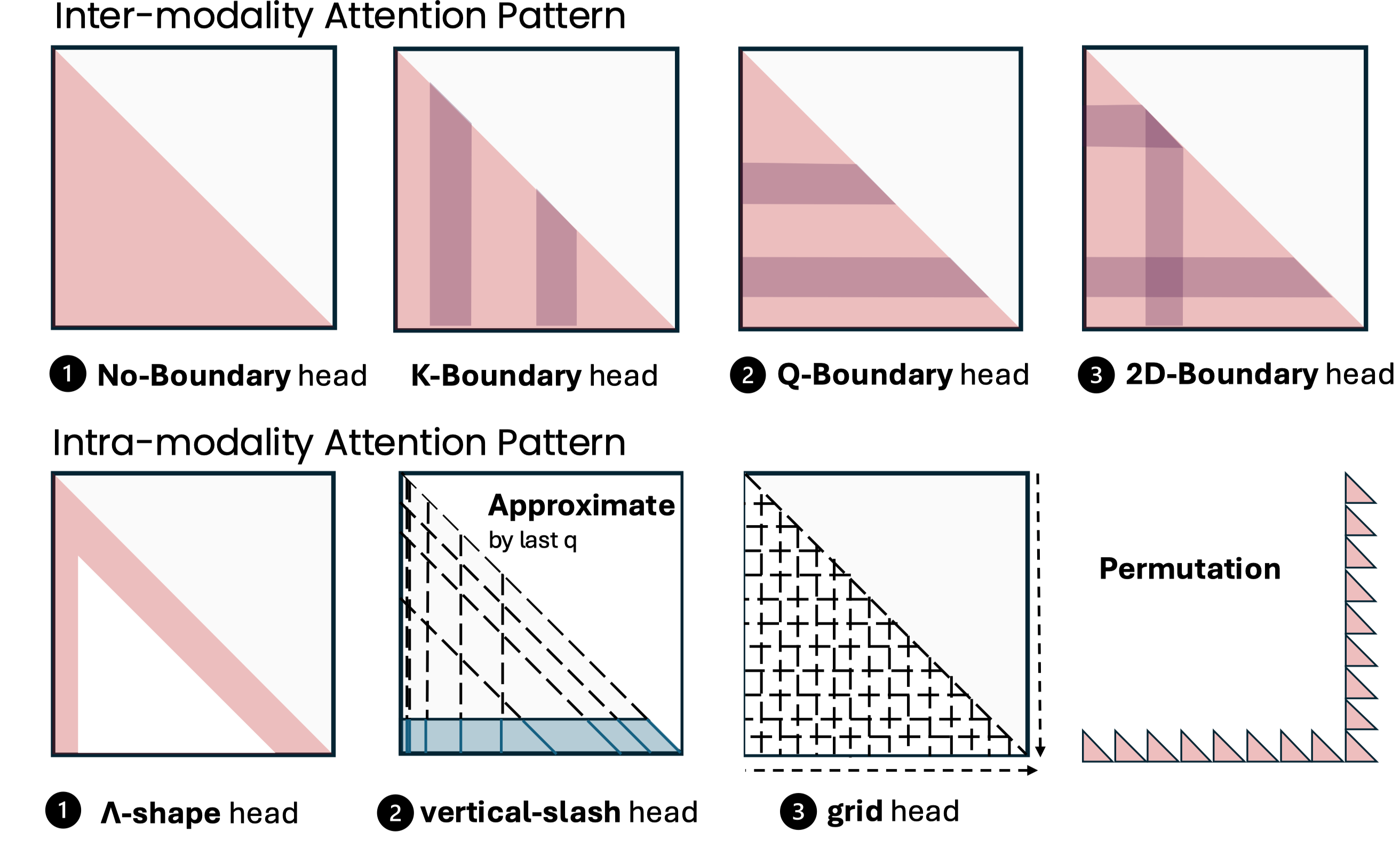
title={{MMI}ference: Accelerating Pre-filling for Long-Context VLMs via Modality-Aware Permutation Sparse Attention},
author={Li, Yucheng and Jiang, Huiqiang and Zhang, Chengruidong and Wu, Qianhui and Luo, Xufang and Ahn, Surin and Abdi, Amir H and Li, Dongsheng and Gao, Jianfeng and Yang, Yuqing and Qiu, Lili},
booktitle={Forty-second International Conference on Machine Learning},
year={2025},
url={https://openreview.net/forum?id=me6PfbATWM}
}